스프링 배치를 접하며 깨달은 점 3가지 써본다. 주관적인 견해도 함께 포함된다.
1. 테스트 코드에 @Transactional을 쓸 수 없다.
배치는 보통 데이터를 핸들링 하는 기능이기 때문에 데이터가 필수적이다. 그러므로 테스트 시작 전에 테스트 데이터를 임시로 적재할 필요가 있다. 이때 테스트 코드 상단에 @Transactional을 명시하여 시작 전에 적재 예정 데이터들을 테스트 종료 시 Rollback 하면 편하다.
하지만 테스트 코드에 @Transactional을 사용하면 아래와 같은 오류를 뱉어낸다.
@Transactional
@SpringBatchTest
@SpringBootTest
@Transactional // <- spring batch 구동 전 외부 트랜젝션
class SampleJobTest {
void jobTest() throws Exception{
...
}
}"java.lang.IllegalStateException: Existing transaction detected in JobRepository. Please fix this and try again (e.g. remove @Transactional annotations from client)."
JobRepository에서 기존 트랜잭션이 감지되었다고 한다.
테스트 코드에서 @Transacional 선언 시 오류가 나는 이유는 다음과 같다.
spring batch는 최상위 Transaction을 갖고 구동되고, 외부의 트랜젝션 선언을 하지 못하도록 제한한다.
spring batch를 구동하기 위해선 meta table에 대한 핸들링(배치 실행, 중, 종료 등)이 필요하다. 개발자가 작성하는 코드로 인해 오류가 났을 때, 이 영향이 meta table을 핸들링하는 트랜젝션에 영향을 주면 안되기 때문이다.
Job을 비정상적으로 종료시키다 보면 가끔 메타 테이블 데이터가 꼬이게되어 원인 모를 실행 오류를 경험한 적이 있을 것이다. spring batch의 중추가 되는 테이블이기 때문에 실행 이력들이 꼬이지 않도록 하기 위한 제한이라고 생각한다.
해결책은 테스트 데이터의 적재와 삭제를 수동으로 하는것이다.
자동으로 테스트 데이터를 적재/삭제 하는 방법은 아직 찾지 못했다.
2. 되도록 Step관련 class를 추가 생성하지 말자
Step 하나는 tasklet 혹은 reader, processor, writer로 최대 3개의 클래스가 생성될 수 있다.
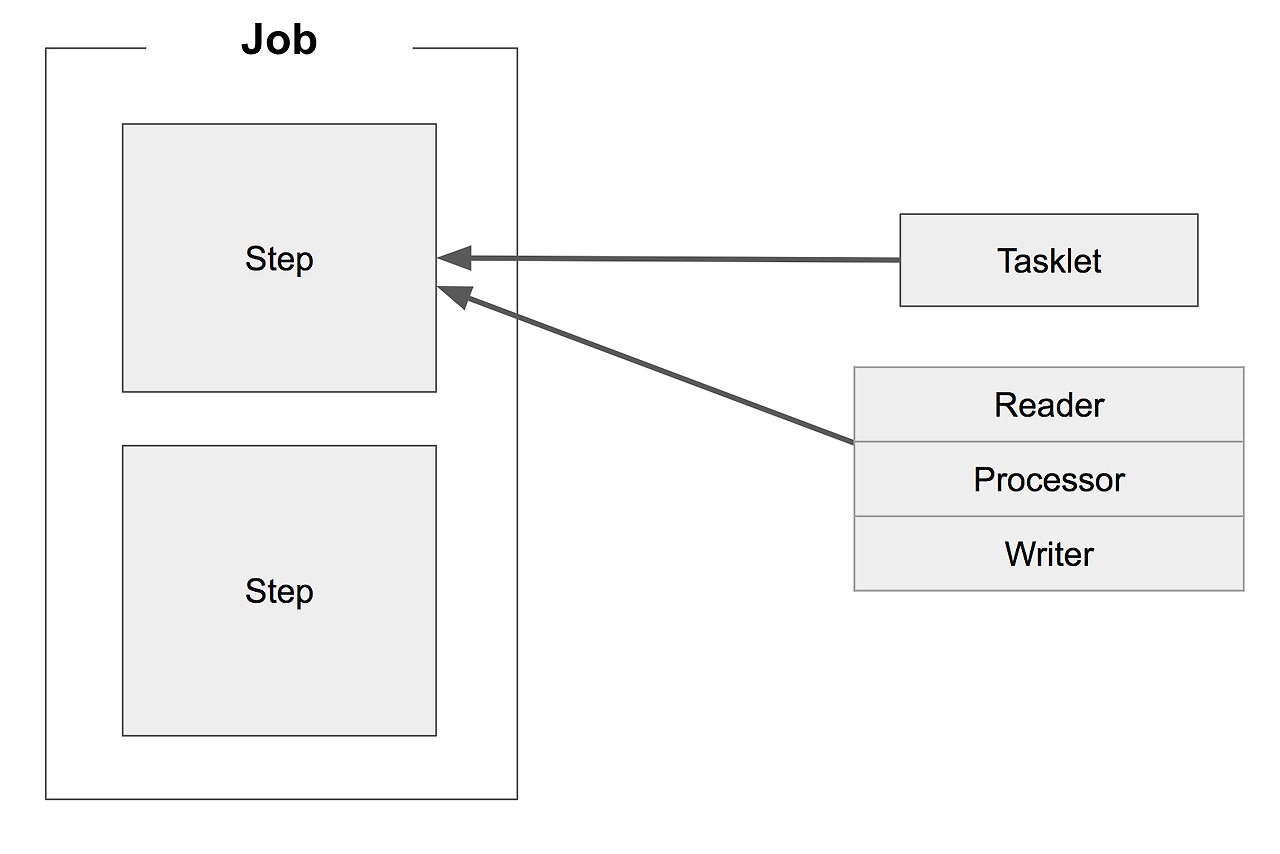
여러 Step을 구현한다면 최대 +3n개 씩 증가하므로 프로젝트를 비대하게 만든다. Job class가 길어지더라도 그 안에 정의하는 것이 더 낫다고 생각한다.
이것을 실현하기 위해서는 Spring batch에서 지원하는 구현체(JdbcItemReaer, JpaItemReader 등)를 사용하거나 필요 시 구현체를 만들어서 사용해야한다. 공통 구현체가 없다면, 별도의 class를 생성 및 상속받아 구현해야하는 번거로움이 있다
// 1. 공통 구현체 이용(X)
public class ProductRepositoryItemReader extends AbstractPagingItemReader<Product> {
private final ProductBatchRepository productBatchRepository;
private final LocalDate txDate;
public ProductRepositoryItemReader(ProductBatchRepository productBatchRepository,
LocalDate txDate,
int pageSize) {
this.productBatchRepository = productBatchRepository;
this.txDate = txDate;
setPageSize(pageSize);
}
@Override // 직접 페이지 읽기 부분 구현
protected void doReadPage() {
if (results == null) {
results = new ArrayList<>();
} else {
results.clear();
}
List<Product> products = productBatchRepository.findPageByCreateDate(txDate, getPageSize(), getPage());
results.addAll(products);
}
@Override
protected void doJumpToPage(int itemIndex) {
}
}
@Slf4j
@RequiredArgsConstructor
@Configuration
public class QuerydslPagingItemReaderConfiguration {
private final ProductRepositoryItemReader productRepositoryItemReader
}// 2.공통 구현체 이용(O)
@Slf4j
@RequiredArgsConstructor
@Configuration
public class QuerydslPagingItemReaderConfiguration {
// ...
@Bean
public QuerydslPagingItemReader<Product> reader() {
return new QuerydslPagingItemReader<>(emf, chunkSize, queryFactory -> queryFactory
.selectFrom(product)
.where(product.createDate.eq(jobParameter.getTxDate())));
}
}
* 코드 참조 : https://jojoldu.tistory.com/455
3. Job, Step 1:1 관계 단점
과거에 멋진 글을 보았다. Job을 생성할 때 하나의 Step만을 생성하여 나름 한가지 책임만 갖는 Job을 만들고, 여러 Job들의 흐름을 그룹으로 묶어서 스케줄러로 컨트롤하는 것.
- 배치와 스케줄러의 기능을 완전히 분리.
- 한가지 책임을 갖는 Job.
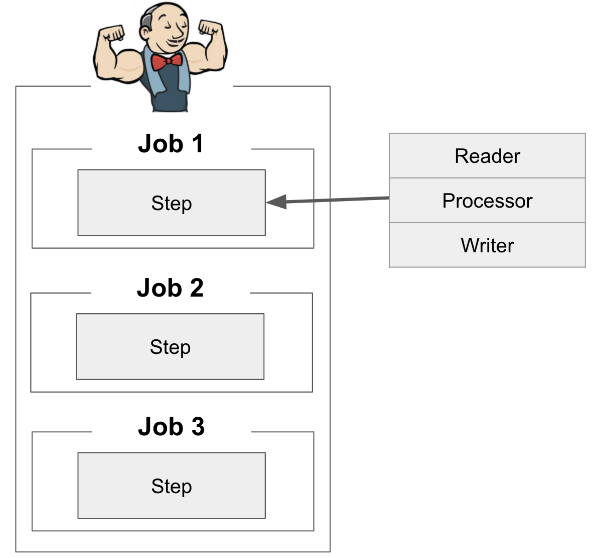
하지만 이걸 실무에 반영할 때 고민이 생겼었다.
Job은 파라미터를 주입받아 실행된다.
1. 하나의 Job을 실행할 때 예시
param1, param2 => JobA 실행!!
2. 여러개의 Job을 실행할 때 예시
group(
param1, param2 => JobA 실행!!
param1, param3 => JobB 실행!!
param4 => JobC 실행!!
)
여러개를 실행할때 2.처럼 중복 파라미터(param1)가 발생할 수 있다. 그렇다고 하나만 선언해 놓자니 추후 어떤 Job에서 공통으로 사용하는 파라미터인지 헷갈린다. 어쩔 수 없이 소스를 들여다봐야하는 상황이 될 수 있다.
아직 멋진 구조를 생각해내진 못했지만,
실행 방법 표준을 정하고 배치를 개발하는 것이
추후 예상치 못한 문제(스케줄러 or 파라미터)를 미리 예방할 수 있는 방법인 것 같다.